TL;DR: Many badges were broken since they were using the shuttered pypip.in site. I wrote a bot that could fix these and automatically submit pull requests with the changes. And then I had my GitHub account suspended. Do not make automatic unsolicited pull requests.
Disclaimer
This post discusses the design decisions that went into a bot that I built to interact with the GitHub API. In the end, GitHub doesn’t want you to do this kind of automation. I left the blog post as I had originally written it, but that is only because the ideas are applicable to any bot, not just ones that might violate Terms of Service 😉.
Broken Badges!
Recently I was working on a side project that required automatic interaction with a large number of GitHub projects. As part of testing that project, I noticed that there were a lot of badges that were broken.
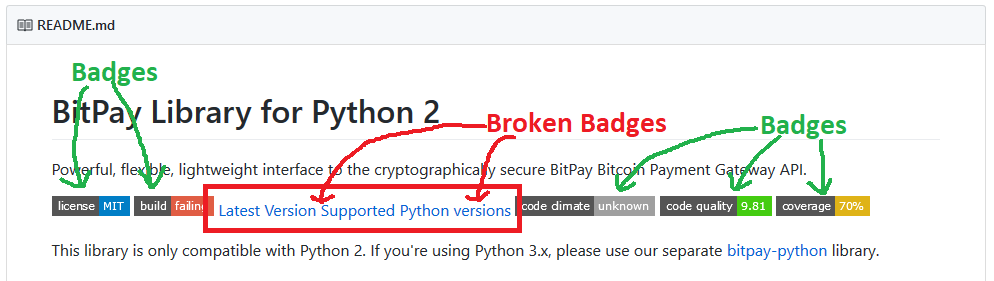
Badges are those cute little colourful rectangles that you see at the top of many READMEs. They often display things like the current version of the software, number of downloads, code coverage, results of vulnerability scans, build status, etc.
However, within the Python community there were many badges that were broken in the package READMEs. These badges were making use of a badge service called pypip.in which apparently stopped operating some time ago (a few years?).
Given that I already had downloaded a list of Python packages for my side project, and their corresponding GitHub READMEs, I decided to see if I could make a bot that could fix these broken badges.
Thankfully, shields.io is still operational and has a very similar API to what pypi.in offered. So the plan was to modify the existing badges to make use of the shields.io API instead.
Initial Development
The code to do this is pretty straight forward. After doing a preliminary scan of the README’s I had already downloaded (as part of another project), I would look for URLs that had that the pypip.in domain. Then I used Python’s regular expression subn function to replace it with a shields.io URL.
PYPIP_REGEX = re.compile(r"http[s]?://pypip.in/([\w.,@?^=%&:/~+#-]*[\w@?^=%&/~+#-])?", flags=re.IGNORECASE) # Based on https://stackoverflow.com/a/6041965
new_readme, n = PYPIP_REGEX.subn(generate_shields_io_url_from_pypip_url), exisitng_readme)
The code that interacts with the GitHub API is where the bulk of the code was. I used the PyGithub library and it wasn’t too bad (though I definitely needed to refer to the official docs at times).
(BTW: the code can be found here. I’m not going to talk much about the code, since the other parts of the project were more interesting. Please feel free to take a look)
Testing
Running a script to modify hundreds of GitHub repos is a scary thing. If you don’t find this idea scary, please don’t write GitHub bots (Post-Suspension Update: actually don’t write bots that do this at all).
Even the smallest bug can cause you to break repos, piss off maintainers, and generally wreak havoc. You’d end up with egg on your face, and have to spend a long time trying to apologize and manually undo the mess.
As a result, testing was very important. I created a TestProject within GitHub that I could use to test the GitHub manipulation code. I also wrote unit tests for the replacement of pypip URLs within the READMEs (though not enough of them, as I eventually found out).
Incremental Rollout
Even still, there are only so many error cases you can reasonably predict and properly defend against. Anytime you have a process that might cause considerable damage, you should start by only working on a small batch and slowly increase your batch size once you have some confidence that everything is working fine. I started with batches of 1 pull request, then worked myself up to 10 pull requests, and eventually 100 pull requests at a time.
Messaging
Automated messages can be super annoying. This is especially true if they are unsolicited. This meant that my bot was at risk of pissing off a lot of library maintainers.
There are four very important things that any automated message needs to do in order to help avoid aggravating people:
- Be Accurate and Useful
- Be Honest/Open about being a bot
- Have a mechanism for feedback
- Be Friendly
Being Accurate and Useful
Nothing is more annoying than irrelevant spam. Maintainers are already under a lot of pressure to triage issues, evaluate pull requests, while also developing new features. And, in most cases, they are doing it all for free. You should be careful not to waste any more of their time than necessary.
Really, this advice is the same whether or not the pull request is automated. But since there is less opportunity for empathy in case of a well-intentioned mistake, automated messages must go the extra mile to get it right.
In my case, it meant putting in the extra effort (and code complexity) to make the message tailored to the nuances of their repository (ie. Not a generic message for all repos). It also meant making sure that the pull request is super simple to review and accept. The goal was to take less than 30 seconds of a maintainer’s time.
Being Honest/Open about being a bot
People do not like automated messages that masquerade as being from a real human. Think about all the “Kelly’s”, “Natasha’s”, and “Lexi’s” that have sent you emails offering to hook up or increase the size of your genitals. Or those “networking” invites on LinkedIn.

Automated messages should describe themselves as such. It should be the opening line. In my case, announcing it as automated helps explain why they are receiving the pull request (especially when the bot finds an abandoned repo or a maintainer gets false impression that I’m a user of their code).
(It also probably helped mitigate anger when my bot made a stupid mistake that would be considered malicious if it were not automated. See Bug #4 below)
Have a mechanism for feedback
In case you still cause aggravation, you should allow the recipient to vent that frustration by providing a mechanism for feedback. Not only will they no longer feel powerless to stop the unsolicited messages, they might provide valuable feedback about how to improve your bot.
On a more selfish note, it also gives happy recipients a mechanism to thank you for your efforts, which of course is good for the feels:

Being Friendly, Humble, and Deferent
As with all your interactions on the Internet, you should be trying to be overly polite and friendly. Everyone comes from a different point of view, so you need to be civil. In this case, they are the maintainer of the repo; they wield ultimate authority over the codebase. If you want them to accept your pull request, you need to make sure that your messaging is friendly, humble, and deferent to their wishes.
I ended up settling on the following message for the pull requests:
Hello, this is an auto-generated Pull Request. (Feedback?)
Some time ago, pypip.in shut down. This broke the badges for a bunch of repositories, including
python-librsync. Thankfully, an equivalent service is run by shields.io. This pull request changes the badges to use shields.io instead.Unfortunately, PyPI has removed download statistics from their API, which means that even the shields.io “download count” badges are broken (they display “no longer available”. See this). So those badges should really be removed entirely. Since this is an automated process (and trying to automatically remove the badges from READMEs can be tricky), this pull request just replaces the URL with the shields.io syntax.
It explains the issue and solution, as well as links them to more information should they want to investigate further. Note that the last paragraph is only included in the message if the README includes the “download count” badges. I debated working out a system to delete these badges automatically, but decided against it due to its complexity (Perhaps in the future I’ll repurpose this bot to remove those).
Tracking
Once I had a script to produce the pull requests, I was nearly ready to unleash it upon the world. However, there is still one very important, easy-to-forget, piece to build.
Keeping a record of what pull requests you created, as well as their merge/close (ie. accept/reject) status is important. Logging the pull request made allows your program to make sure that it doesn’t accidentally create multiple commits or pull requests against the same repo. Keeping track of the merge/close ratio allows you to get a sense for whether or not people are happy with your changes.
Finally, I kept track of the time at which I created the pull requests. This is useful when debugging any issues that arise, because you get an ordered timeline of what your bot did. Having your bot output timestamped logs can also fill this need.
Bugs
When I let the bot loose to process real-world data, despite my testing, it of course had bugs that created problems. Thankfully, I started by only letting it process small batches of repositories, so the results were caught early and didn’t cause too much damage.
The first bug was an issue with the regex I was using, causing it to make a mess of some Markdown links. While I had to manually correct some pull requests and apologize for the trouble, it was an easy fix in the bot code.
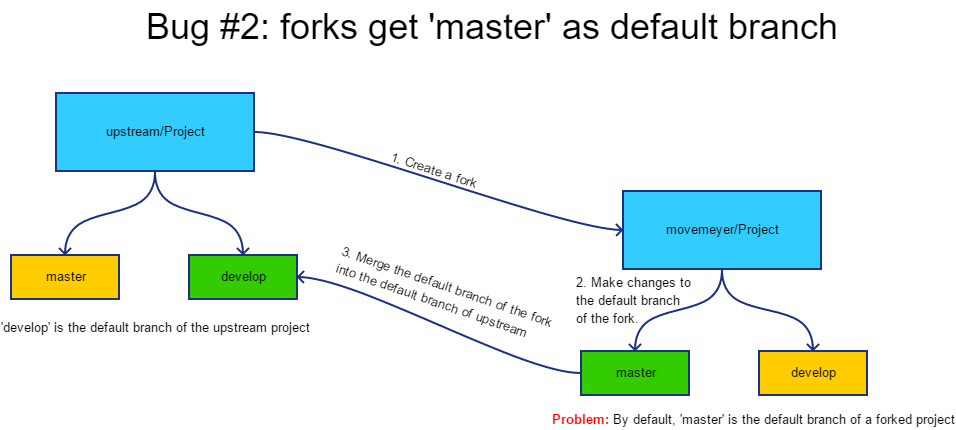
The second bug had to do with repositories that had non-master default branches. My program was written to handle this case, but of course I failed to extensively test this. It would fork a repo that had develop as its default branch, apply the changes to the develop branch and then create a pull request to the upstream repo from the default branch of the fork to the default branch of the upstream. Unfortunately, when you fork a repo, the default branch is not preserved and is set to master. So I was creating pull requests from fork:master to upstream:develop, which caused a mess. The fix was to make sure to use the default branch of the upstream repo, and not the default branch of the fork.
The third bug was a result of a package getting renamed. The bot processed the suite Python package that has its code stored at stevepeak/suite. However, that package was renamed to dictime and stevepeak/suite is actually just a redirect to stevepeak/dictime. So when the bot processed dictime it created a second commit to the same repo and tried to open a second pull request with the same name and branch. Thankfully GitHub raises an error when you try to do that and the bot crashed before it could cause too much damage. This was fixed by using the GitHub API to resolve the project names (ie. follow redirects) before my bot decided whether to process the repository or not.
The fourth bug was a result of multiple forks being published as different packages. For example my code processed the nagobah-with-server Python package which has its repo at littlegump/dagobah, which itself is a fork of tthieman/dagobah. My program correctly made the fork at movermeyer/dagobah and made the pull request for littlegump/dagobah. However, when it came time to process tthieman/dagobah, it tried to once again create a fork at movermeyer/dagobah, and seeing that it already existed, reused it. This resulted in a pull request that tried to apply nagobah-with-server code onto tthieman/dagobah. Ughhh. Thankfully, it only affected two pull requests.
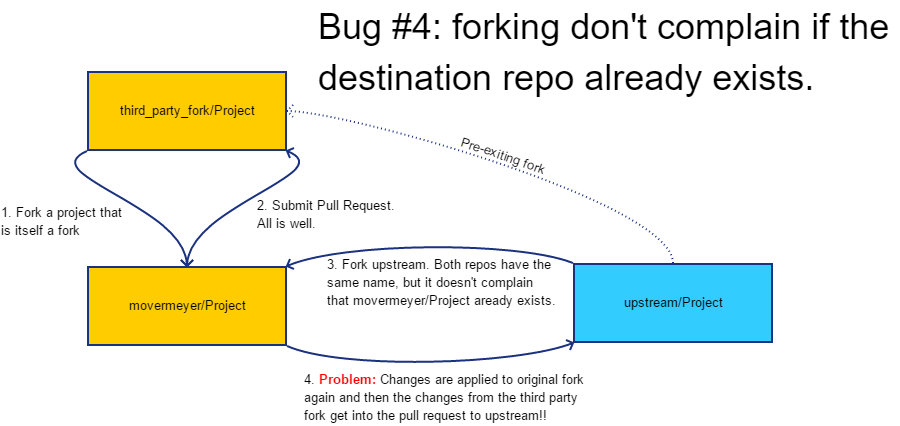
Unfortunately, I never developed a proper fix for this last bug. I added some code to check for an existing fork within the movermeyer namespace, and skipped the package if I had already processed a repo with a similar name. I thought that renaming the first fork to something unique would solve the problem, but it turns out that GitHub is tracking the transitive forking and still considers it to be the same repo.
Results + Feedback
Overall, the results were very positive. The bot made pull requests against 1034 repositories. As of time of writing, 228 of them have been merged, while only 13 were closed (ie. rejected). The ones that were rejected seem to be for repositories that are no longer being maintained, and the maintainers simply closed the pull request by default. One maintainer sent me an email and requested that I add his projects to a blacklist (which I quickly obliged).
I got a lot of happy feedback from maintainers as they merged. I also received some actual emailed feedback from maintainers. Here are my favourites:
The pull request description is great — I’ve been wondering for a while what happened to those images — and providing a solution like you did is just brilliant. -Paul Furley
Paul has actually also created a bot, but his does the more important work of warning people when their PGP keys are about to expire.
Thanks a lot! I forgot to fix it.
thanks auto-generated :)
Nice 👍
All in all, not bad for a quick side project. :)
Update: GitHub account flagged
A few days later, I was trying to run my script to get an updated count of merged pull requests and GitHub returned a “rate limit exceeded” response. This was odd, since I had written my code in such a way that respected their rate limits (at time of writing, 5000 requests/hour). When I manually logged into GitHub.com, I was greeted with the following banner:

My profile was “hidden”, which meant a number of things:
- All the pull requests I have ever made disappeared. The merged code was obviously unaffected, but even the merged pull requests disappeared from the repos.
- All the bug reports and issues I have ever made disappeared
- All my repos disappeared
- All the forks of my private repos disappeared (As GitHub forks of private repos are not real forks)
- My personal site went offline, as it is hosted using GitHub Pages
It was a shocking and immediate reminder of just how much we rely on GitHub and other centralized services. A large chunk of my digital life had been erased. It was as if it had never existed. It was eerie to say the least.
I immediately contacted GitHub support and explained the situation. To their credit, the response came quickly:
Many users consider it spam when a bot posts a pull request to their account – unless they have specifically opted in to be a part of that project. This sort of automated (non-opt-in) activity is disruptive to our users and can be considered a violation of our Terms of Service. We ask that you please refrain from posting these automated Pull Requests on other users’ repositories unless that user has specifically opted in to your service.
After promising not to make any more pull requests, they unflagged my account. All the previously created pull requests returned, and maintainers continued to merge them.
Conclusion + Code
This was a nice side project that taught me a lot. It allowed me to make a bunch of mistakes that I can learn from. If you’re interested in the code, you can find it here.
I fully understand GitHub’s position on this. Unsolicited messaging can be annoying/disruptive. And while I might consider my pull requests beneficial (if a bit trivial), so might any other person consider their bot to be beneficial. Unsurpisingly, this is not GitHub’s first time dealing with bots.
As I briefly hinted at in the beginning of the post, this was meant to be the first step towards a much more complicated (and useful) bot that I was working on. Now it seems that project will have to be scrapped.
As the size and number of the world’s codebases increase, there is an increasing need to manage them in an automated fashion. Automation allows a single developer to have a noticeable impact on the entire ecosystem. Unfortunately, this doesn’t preclude negative impacts, so we are forced to limit its use.
I can’t help but wonder how much better things could be. Perhaps if there was some organization that could vet bots and approve them for use. Then repo owners could opt into receiving messages by all the bots under the organization. Perhaps if there were enough bots and they were useful enough, you could get a large enough following to once again have a out-sized, positive impact. Admittedly, I don’t have a workable solution yet, but I think that coming up with one could allow for wholesale improvements to the entire open-source ecosystem.
In the mean time, I will continue to think, hope, and wish for a better future.